隨著大數據技術的快速發展,數據量的爆炸式增長對存儲和計算能力提出了更高要求。傳統的大數據架構往往將存儲與計算緊密耦合,導致資源利用率低、擴展性差、運維復雜等問題。存算分離架構應運而生,而統一元數據與數據湖Catalog正是實現這一架構的核心支撐。
一、存算分離的挑戰與需求
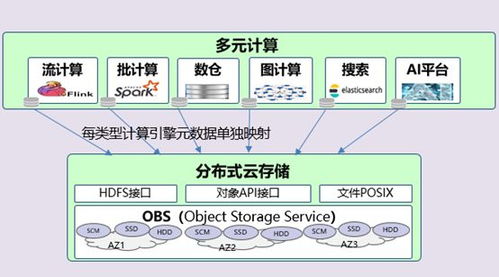
在傳統大數據平臺上,存儲和計算通常部署在同一集群中,數據本地性雖能提升計算效率,但也帶來明顯弊端:資源難以獨立擴展、存儲格式受限、多引擎數據共享困難等。存算分離通過將存儲層與計算層解耦,使兩者能夠按需獨立擴展,大大提升了系統的靈活性與成本效益。分離后的數據如何高效管理、如何確保數據一致性、如何支持多樣化的計算引擎訪問,成為亟待解決的問題。
二、統一元數據的作用
元數據是描述數據的數據,包括數據的結構、格式、位置、權限等信息。在存算分離架構中,統一元數據管理能夠為分布式存儲系統中的數據提供全局視角。通過集中維護元數據,系統可以實現以下優勢:
- 數據發現與目錄化:用戶和應用程序能夠快速查找和訪問所需數據。
- 多引擎支持:統一元數據使得不同計算引擎(如Spark、Flink、Presto等)能夠無縫訪問同一份數據。
- 數據治理與安全:通過統一的權限控制和審計機制,保障數據的安全性與合規性。
三、數據湖Catalog的關鍵角色
數據湖Catalog作為統一元數據管理的具體實現,是大數據存算分離架構中的“數據目錄”。它本質上是一個元數據存儲和查詢服務,能夠對接多種數據源(如HDFS、S3、ADLS等),并提供標準化的數據訪問接口。其主要功能包括:
- 元數據抽象與標準化:將底層存儲的細節封裝起來,向上提供統一的數據視圖。
- 數據版本管理與ACID事務支持:確保在并發訪問場景下的數據一致性。
- 跨區域與多云數據集成:幫助企業整合分布在多個環境中的數據,實現全局數據治理。
四、實踐案例與未來展望
目前,業界已有多個開源與商業產品支持數據湖Catalog功能,如Apache Hive Metastore、AWS Glue Data Catalog、Alibaba Cloud Data Lake Formation等。這些工具通過提供完善的元數據管理能力,有效支撐了存算分離架構的落地。例如,某電商企業通過引入統一元數據與數據湖Catalog,將其數據平臺從傳統的Hadoop集群遷移至云上對象存儲,實現了存儲成本降低40%的同時,計算資源彈性擴展能力提升3倍。
未來,隨著數據湖技術的成熟,統一元數據與數據湖Catalog將進一步與AI、數據編織(Data Fabric)等新興技術融合,推動大數據架構向更智能、更自動化的方向發展。企業應積極擁抱這一趨勢,構建以數據湖為核心的新一代數據平臺,充分釋放數據價值。
統一元數據與數據湖Catalog不僅解決了大數據存算分離的技術難題,更為企業數據架構的現代化演進提供了堅實基礎。通過它們,企業能夠實現數據資源的統一管理、高效利用與敏捷創新,真正邁向數據驅動的未來。